
定义
监督学习是学习一种映射函数从一组输入变量到目标变量的过程。这里的监督指的是通过我们知道目标结果,即正确答案来监督算法的训练过程。但如果只有一组变量而没有相应的输出变量(即数据没有标记),那么这个过程被称为无监督学习[1]。
在无监督学习中,训练过程没有正确的答案可以提供学习,学习算法只能发现数据集中的结构[2]。无监督学习主要用途有两类:1.聚类;2.降维。
聚类:它是根据某种相似性度量(如距离)对一组数据点进行划分的过程。聚类的目的是揭示异构数据中的子组,这样每个单独的聚类都比整体具有更大的同质性。
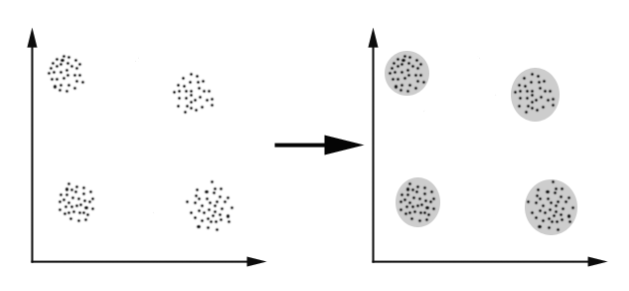
有很多相似性度量的方法,如:
(1)衡量向量的相似性:Cosine距离
![]()
(2) 衡量数据集的相似性:Jaccard距离
![]() (if A和B都是空集,我们定义J(A,B)=1,0≤ J(A,B) ≤ 1 )
(if A和B都是空集,我们定义J(A,B)=1,0≤ J(A,B) ≤ 1 )
(3) 衡量坐标点的相似性:Euclidean距离
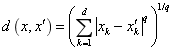 (q是坐标点的个数)
(q是坐标点的个数)
降维:其目标是识别数据特性中的模式。降维通常用于促进数据的可视化,以及监督学习之前的预处理方法。
参考文献
[1] Alashwal H, El Halaby M, Crouse J J, et al. The application of unsupervised clustering methods to Alzheimer’s Disease[J]. Frontiers in computational neuroscience, 2019, 13: 31.
[2] Eick C F, Zeidat N, Zhao Z. Supervised clustering-algorithms and benefits[C]//16Th IEEE international conference on tools with artificial intelligence. IEEE, 2004: 774-776.

