
定义
Noise2Noise 是由NVIDIA公司的Jaakko等人在2018年计算机顶会CVPR发布的一种基于深度学习方案的视频去噪方法,网络架构是U-Net[1]。该方法避免使用干净的视频作为训练的参考,而是使用含噪声的样本对进行训练,达到了与使用干净样本训练近乎相同的效果。
思想
核心思想是L2损失函数的使用。2017年,Ledig 等人在超分辨方面的研究工作指出,使用L2损失函数对(低分辨,高分辨)图像对进行网络训练时,预测出的图像,其边缘纹理细节是模糊的,这似乎好理解:一张低分辨率图像可以被多种高分辨率图像所解释,因此站在损失最低的角度,网络通常会输出高分辨率图像的平均水平(高斯模糊)。但是对于图像视频去噪而言,如果网络倾向于输出样本的平均水平,那么去噪任务中干净图像可以被含噪图像所替代。
为什么L2损失函数会导致优化的结果是输出样本的平均水平?举例而言,对于一维信号去噪,常见的优化方法是:
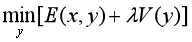
其中x是原始含噪信号,y是期望输出的去噪信号,λ是平衡因子,用于权衡去噪导致的损失E和平滑约束强度V。如果将损失函数E和平滑约束V分别定义为:
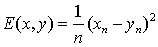

这里xn和yn分别表示原始信号和去噪信号中n时刻的点,那么这个优化问题是基于全变分的去噪方法,核心思想就是约束一阶导数的绝对值总和来保证信号的平滑,由于采用了L2损失函数E,得到的效果如下:
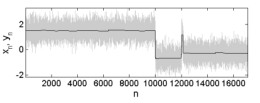
图 1 基于L2损失函数的一维信号全变分去噪效果[2]
这里我们注意到,基于L2损失函数的去噪近似于取了样本的均值。那么对于网络训练而言,优化问题是:
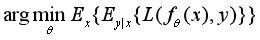
即基于给定样本集x训练得到一组网络参数θ,使与参考样本的损失L最低。同样,这里L通过L2损失函数来定义,则有如下的结果:
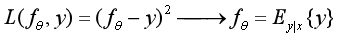
可以看到,最终训练获得的网络参数θ之和参考样本的期望有关,而和任何一个单独的样本无关。因此无论是采用干净的图像还是使用均值为零的含噪图像作为参考图像,在样本无穷的情况下,对于网络的训练没有区别。
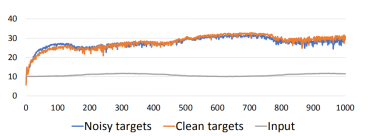
图 2 实测结果,表明噪声样本和干净样本用于训练时,最终去噪效果差别并不大
优缺点
优点是不再使用干净的图像作为网络训练的参考图像,而干净的图像往往是不存在的。
缺点是要求噪声必须为均值为0的高斯加性噪声,其它类型的噪声必须经过转换后才可以使用本方法。另外,本方法适用于视频去噪,对于单张图像则需要考虑其升级版Noise2Void。
参考文献
[1] Lehtinen, Jaakko, et al. "Noise2noise: Learning image restoration without clean data." arXiv preprint arXiv:1803.04189 (2018).
[2] Little, M. A.; Jones, Nick S. "Sparse Bayesian Step-Filtering for High-Throughput Analysis of Molecular Machine Dynamics" . ICASSP 2010.

