
定义
k-means是采用均值算法把数据分成K个类的一种聚类算法。
K 均值算法(K-Means algorithm)是最常用的聚类算法之一,属于划分聚类方法。K-means算法是很典型的基于距离的聚类算法,采用距离作为相似性的评价指标,也就是说两个对象的距离越近,其相似度就越大。算法的最终目的是通过迭代把数据集划分为不同的类别(或称簇),使得评价聚类性能的准则函数达到最优,使得每个聚类类内紧凑,类间独立。
根据以上描述,我们大致可以猜测到实现kmeans算法的主要三点[1] :
(1)簇个数 k 的选择
(2)各个样本点到“簇中心”的距离
(3)根据新划分的簇,更新“簇中心”
通常对于K-means算法而言,k值的选择一般是按照实际需求进行决定,在实现算法时直接给定 k 值。距离的度量一般可以用欧氏距离(Euclidean distance)、曼哈顿距离(Manhattan distance)等多种距离的度量方法[1] 。
K-means聚类算法的一般步骤:
- 初始化。输入基因表达矩阵作为对象集X,输入指定聚类类数k,并在X中随机选取k个对象作为初始聚类中心。为避免运行时间过长,通常需要设定迭代中止条件,比如达到最大循环次数或者聚类中心收敛误差小于预设值。
- 进行迭代。根据相似度准则将数据对象分配到最接近的聚类中心,从而形成一类。初始化隶属度矩阵。
- 更新聚类中心。然后以每一类的平均向量作为新的聚类中心,重新分配数据对象。
- 反复执行第二步和第三步直至满足中止条件[2] 。
我们以图1为例,看一下k=2时聚类的具体迭代过程。

图 1 K-means聚类示意图[3]
K-means算法的不足
由于K-means算法中k是事先给定的,因此k值的选定有时非常难以估计。很多时候,事先并不知道给定的数据集应该分成多少个类别才最合适。这也是K-means算法的一个不足。此外在K-means算法中,首先需要根据初始聚类中心来确定一个初始划分,然后对初始划分进行优化。这个初始聚类中心的选择对聚类结果有较大的影响,一旦初始值选择的不好,可能无法得到有效的聚类结果。如图2所示,由于初始的聚类中心选择不当,最终聚类效果很差。
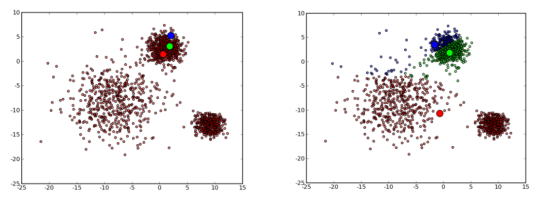
图 2 聚类失败示例图[4]
参考文献
[1] https://www.cnblogs.com/lliuye/p/9144312.html
[2] http://baike.baidu.com/link?url=M1W2aecmVFTxedohDuf65yxhcTqBnXMypb4qVAfro4WYTv_Zlk2b093Zr5B2w-S2N8S1E6WLneiwL9odRFBvCq
[3] http://shiyanjun.cn/archives/539.html
[4] https://www.cnblogs.com/moondark/archive/2012/03/08/2385770.html

