
定义
弱监督学习是机器学习领域中的一个分支,与传统的监督学习相比,其使用有限的、含有噪声的或者标注不准确的数据来进行模型参数的训练。
弱监督学习的分类
按照数据的标注程度可以分为以下三类:不完全监督、不确切监督、不准确监督。
1、不完全监督
若样本中存在部分数据具有标注信息,而剩余部分则不具备有效的标注,这种为不完全监督。进一步,如果对于选定的未标注数据,存在一个系统能够给出数据的正确标签,即具备查询功能,则为不完全监督中的主动学习,其余的可划分为半监督学习的范围。
在半监督学习中,对于数据的分布存在两种基本假设:聚类假设和流行假设。前者假设样本空间存在内在的聚类结构,因此同一聚类中样本的标签应该相同;而后者则认为数据分布在一个流行上,在流行上相近的样本具有相似的预测结果。
2、不确切监督
当数据只具有粗粒度的标签时,被称为不确切监督。例如在人脸识别任务中,只对样本中是否含有人脸进行说明,但不提供人脸的具体位置,便是一种典型的不确切监督的问题。
3、不准确监督
即样本虽有具有标签,但并不准确。造成这种现象的原因有很多,例如标注难度大、标注人员自身水平有限等。
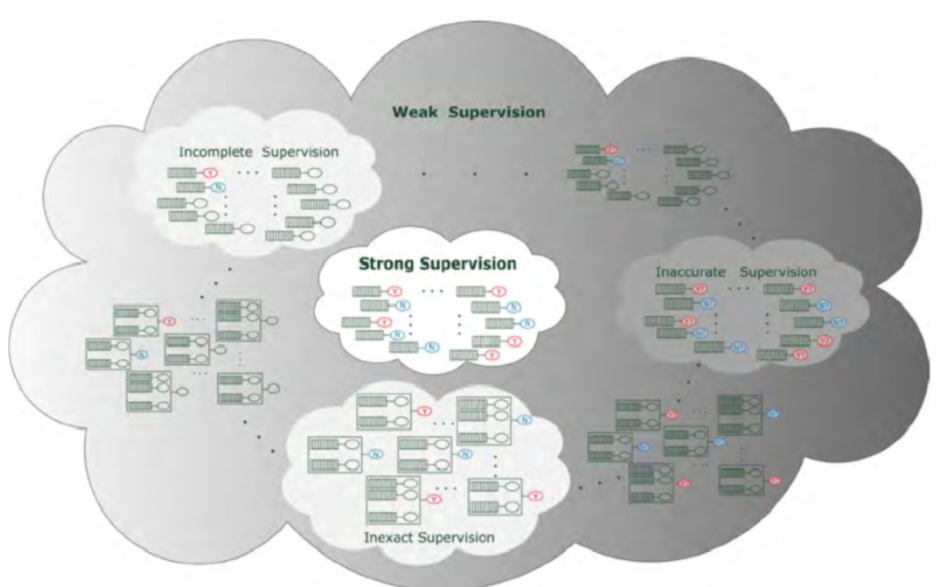
图 1 弱监督学习的分类
弱监督学习在医学影像中的应用
医学影像因标注要求高、数据收集困难等特点,很难收集具有大量有效标注的医学影像,因此很多医学影像分析的工作均采用弱监督学习的思路尝试解决问题。弱监督学习在标签有限的情况下,进行医学影像的处理,进而实现疾病的分类、病灶的定位及分割多种任务。
参考文献
[1] Zhou Z H. A brief introduction to weakly supervised learning[J]. National Science Review, 2018, 5(1): 44-53.

