
定义
循环神经网络(RNN)是一类人工神经网络,其中节点之间的连接沿时间序列形成有向图,从而使其具有时间动态行为[1]。
RNN源自前馈神经网络,可以使用其内部状态(内存)来处理可变长度的输入序列。这使得它们适用于诸如未分段的,连接的手写识别或语音识别之类的任务。
历史
传统的神经网络一个输入对应一个输出,前一个输入和后一个输入是完全没有关系的。但是,某些任务需要能够更好的处理序列的信息,即前面的输入和后面的输入是有关系的。比如,当我们在理解一句话意思时,孤立的理解这句话的每个词是不够的,我们需要处理这些词连接起来的整个序列;当我们处理视频的时候,我们也不能只单独的去分析每一帧,而要分析这些帧连接起来的整个序列。因此RNN应运而生。
RNN是基于大卫·鲁梅尔哈特1986年的工作被创造出来的。1982年,约翰·霍普菲尔德发现了Hopfield神经网络——一种特殊的RNN。Hochreiter和Schmidhuber于1997年发现了长短期记忆(LSTM)网络,克服了传统RNN的梯度爆炸问题,在语音识别等领域被广泛应用。
基本结构[2]
全连接RNN(Fully-Connected RNN)
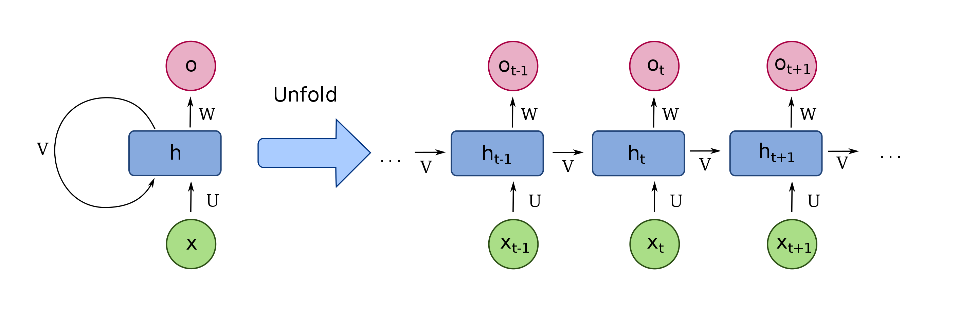
RNN示意图
基本的RNN结构如上图左所示, x是一个向量,它表示输入层的值;h是一个向量,它表示隐藏层的值,可以对序列形的数据提取特征,接着再转换为输出;U是输入层到隐藏层的权重矩阵,o也是一个向量,它表示输出层的值;V是隐藏层到输出层的权重矩阵。隐藏层中的每个节点都通过定向(单向)连接与下一个隐藏层节点连接,展开后如上图右侧所示,当前t时刻h的取值由下式得到:
![]()
其中,ht为当前时刻的隐藏节点取值;xt为当前的输入节点值,f为激活函数。输出对应为:
![]()
经典RNN已经被广泛应用于:计算视频中每一帧的分类标签以及语言生成(Char RNN)。在训练RNN时,一般采取反向传播进行训练,但是在序列较长的情况下,h中权重V的累乘容易造成梯度爆炸或消失,使得训练无法继续。
LSTM(Long Short Term Memory)
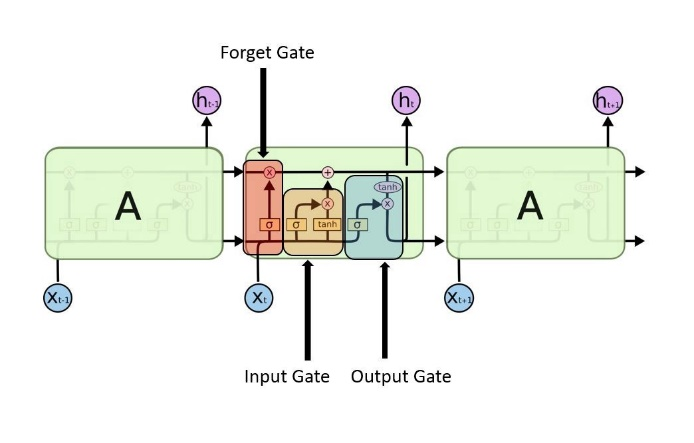
LSTM示意图
长短期记忆(LSTM)网络是循环神经网络的修改版本,解决了RNN消失的梯度问题并使用反向传播训练模型。 LSTM结构如上图所示,常见的LSTM由一个单元,一个输入门,一个输出门和一个忘记门组成。单元会记住任意时间间隔内的值,并且三个门通过门控状态来控制传输状态,记住需要长时间记忆的,忘记不重要的信息,但也因为引入了很多内容,导致参数变多,也使得训练难度加大了很多。
GRU(Gate Recurrent Unit)
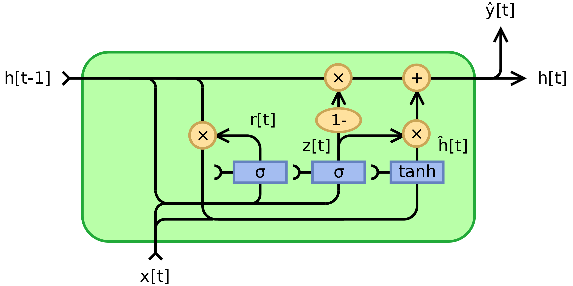
GRU示意图
GRU是循环神经网络和LSTM(Long-Short Term Memory)一样,也是为了解决长期记忆和反向传播中的梯度等问题而提出来的, GRU就像带有忘记门的LSTM,但由于缺少输出门,因此其参数比LSTM少。GRU在复音音乐建模和语音信号建模的某些任务上的性能与LSTM相似。事实证明,GRU在某些较小的数据集上表现出更好的性能。
RNN的应用
目前,由于RNN在时间序列相关任务上的出色表现,其已经被广泛应用于机器翻译、时间序列预测[3]、语音识别[4]、音乐创作[5]、语法学习[6]等领域。
参考文献
[1] https://en.wikipedia.org/wiki/Recurrent_neural_network
[2] Jozefowicz R, Zaremba W, Sutskever I. An empirical exploration of recurrent network architectures[C]//International conference on machine learning. 2015: 2342-2350.
[3] Schmidhuber J, Wierstra D, Gomez F J. Evolino: Hybrid neuroevolution/optimal linear search for sequence prediction[C]//Proceedings of the 19th International Joint Conferenceon Artificial Intelligence (IJCAI). 2005.
[4] Graves A, Schmidhuber J. Framewise phoneme classification with bidirectional LSTM and other neural network architectures[J]. Neural networks, 2005, 18(5-6): 602-610.
[5] Eck, Douglas and Jürgen Schmidhuber. “Learning the Long-Term Structure of the Blues.” ICANN (2002).
[6] Gers F A, Schmidhuber E. LSTM recurrent networks learn simple context-free and context-sensitive languages[J]. IEEE Transactions on Neural Networks, 2001, 12(6): 1333-1340.

