
全称:Multi-Domain Convolutional Neural Networks
MDnet[1]是基于CNN特征表示的目标跟踪模型,在2016年CVPR(Conference on Computer Vision and Pattern Recognition)会议上由Hyeonseob Nam和Bohyung Han提出,此神经网络提出的模型能很好地应用到目标跟踪的任务上,在2015VOT准确度比赛中获得了第一名。
网络结构
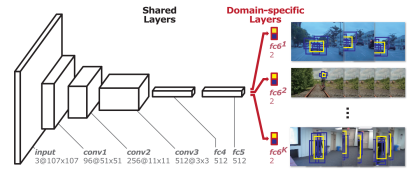
图 1 MDnet结构图
MDnet将跟踪问题视为前景和背景(目标物体和背景)的二分类问题,将每一个视频看做是一个单独的域(domain),基于共享卷积网络,从多个标注的视频序列中学习目标物体的共享表示,并在目标背景区分时连接单独的网络分支,即域特定层(domain-specific layer),进行目标物体和背景的二分类。
网络的体系结构如图1所示,驶入为107×107大小的RGB图像,并具有五个隐藏层,包括三个卷积层(conv1-3)和两个全连接层(fc4-5)。另外,网络最后对于K个域(K个训练序列)对应的全连接层具有K个分支(fc6.1-fc6.K)。每个K分支包含一个具有交叉熵损失的二分类层,它负责区分每个域(训练视频)中的目标和背景。将fc6.1 -fc6.K称为域特定层(domain-specific layer),将之前的所有层称为共享层(shared layers),经过样本训练得到的共享层(shared layers)是一个相对通用的特征提取器,而域特定层(domain-specific layer)针对任务和数据集的不同进行自适应调整,即,MDnet通过共享层提取了普遍的目标特征,域特定层能够得到不同域(视频)的信息。
网络训练及应用
网络训练
在网络训练时,目标是训练一个多域共享的卷积神经网络(multi-domain CNN)可以在任何视频中辨别目标和背景,虽然来自不同视频的训练数据对于目标和背景的定义各不相同,但其中仍然存在着一些共同的属性,如:光照变化,运动模糊,尺寸变化等。提取出满足上述属性的共性特征即可实现目标。
[1]中使用随机梯度算法(SGD)来更新网络参数,共享层被每个训练数据更新,但每个分支对应的全连接层用其对应的视频序列来迭代更新。
网络在线更新
MDnet中采用了困难小批次样本挖掘( Hard Minibatch Mining )[3],使用假阳性(false positives)的样本进行在线网络更新,在学习过程的每一次迭代中,选取选择具有最高阳性分数(positive scores)的若干负样本(背景)作为困难样本。
目标跟踪
在跟踪目标时,每次输入一张图片,以上一帧的目标位置为中心、以多维高斯分布的形式进行采样256个候选框并大小统一维度为107x107,并分别作为网络的输入进行计算他们的目标概率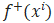 和背景概率
和背景概率 并选取最大对应的候选框作为目标框。将目标框进行边框回归[2](bounding box regression)后得到最终目标框。
并选取最大对应的候选框作为目标框。将目标框进行边框回归[2](bounding box regression)后得到最终目标框。
参考文献
[1] Nam H , Han B . Learning Multi-Domain Convolutional Neural Networks for Visual Tracking[J]. 2015.
[2] Shaoqing Ren, Kaiming He, Ross Girshick Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks[J]. IEEE Transactions on Pattern Analysis & Machine Intelligence, 39(6):1137-1149.
[3] K.-K. Sung and T. Poggio. Example-based learning for viewbased human face detection. IEEE Trans. Pattern Anal. Mach. Intell., 20(1):39–51, 1998.

